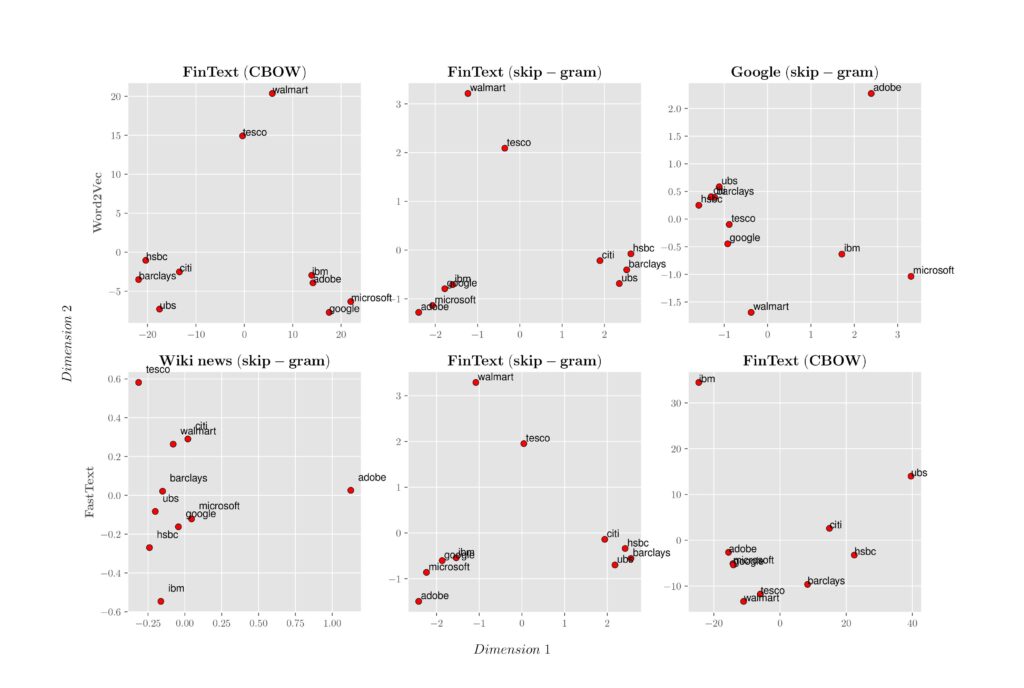
The figure below presents the 2D visualisation of the principal component analysis (PCA) of the word embedding 300-dimensional vectors. Dimension 1 (x-axis) and Dimension 2 (y-axis) show the first and second obtained dimensions. The tokens are chosen from groups of technology companies (‘microsoft’, ‘ibm’, ‘google’, and ‘adobe’), financial services and investment banks (‘barclays’, ‘citi’, ‘ubs’, and ‘hsbc’), and retail businesses (‘tesco’ and ‘walmart’). Word2Vec is shown in the top row, and FastText is shown in the bottom row. Google is a publicly available word embedding trained on a part of the Google News dataset, and WikiNews is another publicly available word embedding trained on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset. The continuous bag of words (CBOW) and skip-gram are the proposed supervised learning models for learning distributed representations of tokens. The expected visualisation for the best word embedding is when tokens in different company groups make clusters. This figure shows that only FinText clusters all sector groups correctly.
Word embeddings are expected to solve word analogies such as king:man :: woman:queen. The table below lists the responses for some financial challenges produced by these word embeddings. It is clear that FinText is more sensitive to financial contexts and able to capture very subtle financial relationships.
| Analogy | WikiNews | FinText | |
|---|---|---|---|
| debit:credit::positive:X | positive | negative | negative |
| bullish:bearish::rise:X | rises | rises | fall |
| apple:iphone::microsoft:X | windows_xp | iphone | windows |
| us:uk::djia:X | NONE | NONE | ftse_100 |
| microsoft:msft::amazon:X | aapl | hmv | amzn |
| bid:ask::buy:X | tell | ask- | sell |
| creditor:lend::debtor:X | lends | lends | borrow |
| rent:short_term::lease:X | NONE | NONE | long_term |
| growth_stock:overvalued::value_stock:X | NONE | NONE | undervalued |
| us:uk::nyse:X | nasdaq | hsbc | lse |
| call_option:put_option::buy:X | NONE | NONE | sell |
We also challenged all six word embeddings to return three top tokens that are closest to ‘morningstar’. For Google Word2Vec, This token is not among the training tokens. The answer from WikiNews is {‘daystar’, ‘blazingstar’, and ‘evenin’} which is wrong. The only logical answer is from FinText (Word2Vec/skip-gram) {‘researcher_morningstar’, ‘tracker_morningstar’, and ‘lipper’}. When asked to find the unmatched token in {‘usdgbp’, ‘euraud’, ‘usdcad’}, a collection of exchange rates mnemonics, the results were as follows: Google Word2Vec and WikiNews could not find these tokens, while FinText (Word2Vec/skip-gram) produces the sensible answer, ‘euraud’.